Applying The Clean Architecture to Go applications
What this text is about
I would like to contribute to Uncle Bob’s concept of The Clean Architecture by demonstrating how its principles could be applied to an actual Go application. It doesn’t make much sense to completely rephrase Uncle Bob’s blog post here, thus reading his text first is definitely a prerequisite for understanding mine.
In it, he mainly describes the Dependency Rule, which, when applied to an architecture where different areas of the software are organized as circles within other circles, says “…that source code dependencies can only point inwards. Nothing in an inner circle can know anything at all about something in an outer circle. In particular, the name of something declared in an outer circle must not be mentioned by the code in an inner circle. That includes functions, classes, variables, or any other named software entity.”
In my opinion, the Dependency Rule is the single most important rule that must be applied when building software systems whose parts are to be testable and independent of frameworks, UIs, or databases. When following this rule, one ends up with a loosely coupled system with clear separation of concerns.
Decoupled systems
Systems whose parts are testable and loosely coupled are systems that can grow without pain, that is, systems which can be easily understood, modified, extended, and scaled. I will try to demonstrate that these qualities do in fact emerge when the Dependency Rule is applied.
To do so, I will guide you through the creation of a simple yet complete Go application, while reasoning on when, how and why the concepts of The Clean Architecture should be applied.
The application is a very (very!) rudimentary but working online shopping system which allows to retrieve a list of items, belonging to an order, through an HTTP web service. You can find the source code of the final application, including some unit tests, at https://github.com/manuelkiessling/go-cleanarchitecture.
In order to keep the code graspable, other use cases, like browsing the shop, checkout, or payment, are not implemented. Also, I concentrated on implementing those parts of the code that help explain the discussion of architecture – thus, the code lacks a lot in other regards, for example, there is a lot less error handling than one would expect in a decent application. It also contains a lot of redundancy – that clearly is a code smell, but it allows to read the code from top to bottom without the need to follow redundancy-reducing indirections.
Architecture of the example application
Let’s start by looking at the different areas of our software and their respective place within the architecture. The architecture of our software will be separated into four layers: domain, use cases, interfaces and infrastructure. We will discuss each layer from a high-level perspective, starting at the innermost layer. We will then look at the actual low-level code implementation of each layer, again moving from inner to outer layers.
The domain, or business, of our shopping application is that of human beings shopping for stuff, or, in more formal terms, of customers adding items to orders. We need to represent these business entities and their rules as code in the innermost layer, the domain layer.
What to put where, and why
I chose to talk about customers, and not users. While our application is of course going to have users, these are not of interest when talking about the domain of the application. I believe that if we want to take separation of concerns seriously, we must be very precise when thinking about what to put into which layer – “user” is a concept that has to do with the use cases, but not with the business itself.
Not surprisingly, as software developers, we are used to view things from a very software-centric point of view. Thus, when reasoning about architecture, whenever I feel that I might trap into an obvious decision that might turn out to be very problematic in the long run due to some nasty subtleties, I try to make up metaphors that don’t include computers. What if, for example, the business domain would not be part of a software program, but part of a board game?
Imagine we would have to implement eBay or Amazon as a board game – then the things that would be at the core of the implementation, no matter if it was a computer application or a board game, make up our business domain.
eBay the website and eBay the board game both need buyers, sellers, items, and bids – but only eBay the website needs users, sessions, cookies, login/logout etc.
I call those differences subtle because, when your program is still small, deciding that users and customers could as well be the same thing doesn’t seem like a big deal. It’s one of those things that only much later turn out to be painful to correct. The reason is that for 99% of the stuff the application needs to do, users and customers actually can be treated as being the same – but them being treated the same does not mean that they are the same, and not realizing this distinction will pay out negatively as soon as you reach the point where the remaining 1% comes into play. Our application will have an example of this.
So, while orders and items belong into the domain layer, users, representing a concept of the application at hand, belong into the next layer, use cases.
What else belongs into the use cases layer? The use cases layer is the location within our software where the use cases are implemented that arise from the fact that users of the software want to actually “do” something with the entities of the underlying domain. An example for a use case might be “a customer adds items to an order”. To realize this and other use cases, methods are needed that put the business entities in motion.
While this could be implemented within the domain layer, I recommend against it. The main reason is that use cases are application-specific, while domain entities are not. Imagine two applications for our shop, one that allows customers to browse and buy stuff, and another one that is used by administrators to manage and fulfill placed orders. While the domain entities remain the same in both applications, the use cases are very different: “add item to order” versus “mark order as shipped”, for example. The domain and use cases layers together form the core of our application, representing the realities of the business we are operating in. Everything else is implementation details that are not related to the nature of our business. Our shop might be implemented as a web site or as a standalone GUI application – as long as we do not change the domain entities and the application’s use cases, it’s still the very same shop, business-wise.
We might switch the web service implementation from HTTP to SPDY, or the database from MySQL to Oracle – this doesn’t change the fact that we have a shop with customers that have orders which contain items (domain), and customers that are allowed to place orders, change quantities, and pay (use cases).
At the same time, this is the litmus test for our inner layers – do we have to change even just a single line of code within the use cases or domain layers when switching from MySQL to Oracle (or flat file)?
If the answer is yes, then we violated the Dependency Rule, because we made at least parts of our inner layers depend on parts in the outer layers.
But of course, there is a place for the code that works with the database or handles HTTP requests. The parts of our application that interact with external agencies like a web or database server live inside the interfaces layer.
For example, if our shop is made available as a web site, the controllers that handle an incoming HTTP request have their place within the interfaces layer, because they form an interface between the HTTP server and the application layer. It is events from the outer world, triggered by HTTP requests, mouse clicks in a GUI or remote procedure calls that make our shop run. Without these, the methods in the use cases layer and entities in the domain layer would just “sit there”, doing nothing. But because elements within these inner layers may not interact with or even know about anything in the outer world, interfaces are needed that transform events in the outer world into actions within the inner layers.
If we would like to store our shop’s data, like its items, orders and users, into a database, we also need an interface to the database. This is where application of the Dependency Rule becomes particularly interesting: If the code that builds the underlying SQL statements lives in the interfaces layer, and nothing in the application layer is allowed to call anything in an outer layer, but triggering the persisting of a domain entity does take place in the use cases layer – then how can we avoid violating the Dependency Rule? We will look into this in detail when going through the code.
The last layer is called infrastructure. Distinguishing what belongs to interfaces and what belongs to infrastructure isn’t always straightforward. The definition that makes sense for me is that both contain code that interacts with the outer world, like code that talks to a database, but while the code in interfaces is specific to your program at hand, infrastructure code is not and can be used in completely different applications. For example, while the functions that will handle the HTTP requests to our web service only make sense within our application, net/http from the Go Standard Library is general-purpose code that can be used to create web services for any application. In this sense, large parts of the Go Standard Library lie, conceptually, within the infrastructure layer.
Let’s sum this all up by creating a list of all layers and the parts of our software therein:
-
Domain:
- Customer entity
- Item entity
- Order entity
-
Use Cases:
- User entity
- Use case: Add Item to Order
- Use case: Get Items in Order
- Use case: Admin adds Item to Order
-
Interfaces:
- Web Services for Item/Order handling
- Repositories for Use Cases and Domain entities persistence
-
Infrastructure:
- The Database
- Code that handles DB connections
- The HTTP server
- Go Standard Library
As you can see, this list includes some elements I have not yet talked about – the admin use case and the repositories will be explained in detail when we discuss the implementation.
One last thought before we dive into the code. If we look at how we separated our application, there’s a pattern here. If you look at the several layers and align them along the dimensions of how application-specific the contained code is and how business-specific it is, the pattern becomes apparent:
| Infrastructure | Interfaces | Use Cases | Domain |
| application-agnostic | application-specific | application-specific | application-agnostic |
| business-agnostic | business-agnostic | business-specific | business-specific |
The more you move to the left, the more low-level the code becomes (“put that byte on the wire on port 80…”), the more you move to the right, the more high-level it becomes (“add item to order…”).
Implementing the architecture
The domain
We will first create the domain layer. As said, our application and its use cases will be fully working, but it won’t be a complete shop. Therefore, the code that defines our domain will be short enough to justify putting it into a single file:
$GOPATH/src/domain/domain.go
package domain
import (
"errors"
)
type CustomerRepository interface {
Store(customer Customer)
FindById(id int) Customer
}
type ItemRepository interface {
Store(item Item)
FindById(id int) Item
}
type OrderRepository interface {
Store(order Order)
FindById(id int) Order
}
type Customer struct {
Id int
Name string
}
type Item struct {
Id int
Name string
Value float64
Available bool
}
type Order struct {
Id int
Customer Customer
Items []Item
}
func (order *Order) Add(item Item) error {
if !item.Available {
return errors.New("Cannot add unavailable items to order")
}
if order.value()+item.Value > 250.00 {
return errors.New(`An order may not exceed
a total value of $250.00`)
}
order.Items = append(order.Items, item)
return nil
}
func (order *Order) value() float64 {
sum := 0.0
for i := range order.Items {
sum = sum + order.Items[i].Value
}
return sum
}
It’s immediately apparent that this code does not depend on anything significant – we only import the “errors” package because some methods return an error. Although the domain entities described here will end up as rows in a database, there is no database-related code in sight.
Instead, we define Go interfaces for three so-called repositories. A repository is a concept from Domain-driven Design: it abstracts away the fact that domain entities need to be saved to or loaded from some kind of persistence mechanism. From the domain’s point of view, a repository is just a container where domain entities come from (FindById) or go to (Store).
CustomerRepository, ItemRepository and OrderRepository are only interfaces. They will be implemented in the interfaces layer, because their implementation is an interface between the database and the application. This is how the Dependency Rule can be applied in Go applications – an abstract interface that does not refer to anything in outer layers is defined within an inner layer; its implementation is defined in an outer layer. The implementation is then injected into the layer that wants to use it; in this case, as we will see later, that’s the use cases layer.
This way, the use cases layer can refer to a concept of the domain layer – repositories – while using only the language of the domain layer. Still, the actual code executed is in the interfaces layer.
For every part in every layer, there are three questions of interest: where is it used, where is its interface, where is its implementation?
If we look at the OrderRepository, the answers are as follows: it’s used by the use cases layer, its interface belongs to the domain layer, and its implementation belongs to the interfaces layer.
The Add method of the Order entity, on the other hand, is used by the uses cases layer, too, and also, its interface belongs to the domain layer. But, its implementation belongs there as well, because it doesn’t need anything outside the domain layer itself.
The repository interface declarations are followed by three structs: Customer, Order, and Item. These represent our three domain entities. The Order entity comes with some additional behaviour in form of two methods, Add and value, the latter being only a helper function for internal use. Add implements a domain-specific function that is needed by the use cases.
There are some additional details in this code that are relevant when talking about the overall architecture. As you can see, we added some rules to the Add method. As we will see, our application has several rules in several places, and it’s interesting to discuss which rules belong where.
The first rule here refuses to add those items to a order that are not available – this is clearly a business rule. Not allowing customers to order unavailable items is a rule that applies to the web shop as well as to orders placed via a telephone hotline; it’s nothing that’s specific to (our) software – it’s a rule we decided to enforce business-wise.
The same goes for the rule that orders may not exceed a total value of $250 – no matter if our shop is a web site or a board game, it’s a business rule that always applies.
Other rules live in other places – somewhere, the value of an item has to be saved to a database, and we must take care to only store floats to the value field within our database; however, this is a technical rule, not a business rule, and does not belong into our domain package.
On the other hand, the database interface code and the database itself would happily obey when asked to persist orders whose items exceed a total value of $250 – as this is a business rule, the database and the according interface code simply must not care about it. This example makes a very strong case for what I like so much about what Uncle Bob preaches, because, just imagine doing the exact opposite – for example, adding the $250 order limit rule as a stored procedure in the database. Good luck getting a complete picture of all your business rules once your application grows large. I prefer having it all in one place any day.
The use cases
Let’s now look at the code of the use cases layer – again, this perfectly fits into one file:
$GOPATH/src/usecases/usecases.go
package usecases
import (
"domain"
"fmt"
)
type UserRepository interface {
Store(user User)
FindById(id int) User
}
type User struct {
Id int
IsAdmin bool
Customer domain.Customer
}
type Item struct {
Id int
Name string
Value float64
}
type Logger interface {
Log(message string) error
}
type OrderInteractor struct {
UserRepository UserRepository
OrderRepository domain.OrderRepository
ItemRepository domain.ItemRepository
Logger Logger
}
func (interactor *OrderInteractor) Items(userId, orderId int) ([]Item, error) {
var items []Item
user := interactor.UserRepository.FindById(userId)
order := interactor.OrderRepository.FindById(orderId)
if user.Customer.Id != order.Customer.Id {
message := "User #%i (customer #%i) "
message += "is not allowed to see items "
message += "in order #%i (of customer #%i)"
err := fmt.Errorf(message,
user.Id,
user.Customer.Id,
order.Id,
order.Customer.Id)
interactor.Logger.Log(err.Error())
items = make([]Item, 0)
return items, err
}
items = make([]Item, len(order.Items))
for i, item := range order.Items {
items[i] = Item{item.Id, item.Name, item.Value}
}
return items, nil
}
func (interactor *OrderInteractor) Add(userId, orderId, itemId int) error {
var message string
user := interactor.UserRepository.FindById(userId)
order := interactor.OrderRepository.FindById(orderId)
if user.Customer.Id != order.Customer.Id {
message = "User #%i (customer #%i) "
message += "is not allowed to add items "
message += "to order #%i (of customer #%i)"
err := fmt.Errorf(message,
user.Id,
user.Customer.Id,
order.Id,
order.Customer.Id)
interactor.Logger.Log(err.Error())
return err
}
item := interactor.ItemRepository.FindById(itemId)
if domainErr := order.Add(item); domainErr != nil {
message = "Could not add item #%i "
message += "to order #%i (of customer #%i) "
message += "as user #%i because a business "
message += "rule was violated: '%s'"
err := fmt.Errorf(message,
item.Id,
order.Id,
order.Customer.Id,
user.Id,
domainErr.Error())
interactor.Logger.Log(err.Error())
return err
}
interactor.OrderRepository.Store(order)
interactor.Logger.Log(fmt.Sprintf(
"User added item '%s' (#%i) to order #%i",
item.Name, item.Id, order.Id))
return nil
}
type AdminOrderInteractor struct {
OrderInteractor
}
func (interactor *AdminOrderInteractor) Add(userId, orderId, itemId int) error {
var message string
user := interactor.UserRepository.FindById(userId)
order := interactor.OrderRepository.FindById(orderId)
if !user.IsAdmin {
message = "User #%i (customer #%i) "
message += "is not allowed to add items "
message += "to order #%i (of customer #%i), "
message += "because he is not an administrator"
err := fmt.Errorf(message,
user.Id,
user.Customer.Id,
order.Id,
order.Customer.Id)
interactor.Logger.Log(err.Error())
return err
}
item := interactor.ItemRepository.FindById(itemId)
if domainErr := order.Add(item); domainErr != nil {
message = "Could not add item #%i "
message += "to order #%i (of customer #%i) "
message += "as user #%i because a business "
message += "rule was violated: '%s'"
err := fmt.Errorf(message,
item.Id,
order.Id,
order.Customer.Id,
user.Id,
domainErr.Error())
interactor.Logger.Log(err.Error())
return err
}
interactor.OrderRepository.Store(order)
interactor.Logger.Log(fmt.Sprintf(
"Admin added item '%s' (#%i) to order #%i",
item.Name, item.Id, order.Id))
return nil
}
The use cases layer for our shop mainly consists of a User entity and two use cases. The entity has a repository, just like the entities from the domain layer, because users need to be stored to and loaded from a persistence mechanism.
The use cases are, not surprisingly, functions, i.e., methods on the OrderInteractor struct. That’s not a must – they could be realized as unbound functions as well. However, attaching them to a struct eases injection of certain dependencies, as we will see.
The code above is a prime example for a “what to put where” discussion that lies at the heart of software architecture musings. First of all, the externalities all need to be injected into the OrderInteractor and AdminOrderInteractor by outer layers, and the structs only name things from the use cases layer and inwards. Again, this is all about the Dependency Rule. The way this package is set up, it doesn’t depend on anything outside the domain or the use cases itself – it can, for example, be tested using mocked repositories, or the actual implementation of the Logger could be exchanged without hassle, that is, without the need to change anything in the above code.
Bob Martin writes that use cases “…orchestrate the flow of data to and from the entities, and direct those entities to use their enterprise wide business rules to achieve the goals of the use case.”
If you look at, say, the Add method of OrderInteractor, you see this in action. The method does the orchestration of getting the required objects and putting them to work in a sensible way for the use case to be fulfilled. It manages the error cases that may arise for this specific use case, and it enforces certain rules – however, it’s important to note which rules. The $250 limit rule is handled in the domain layer, because that’s a business rule that transcends all use cases. Checking which users may add items to an order is, on the other hand, use case specific – plus, it contains an entity, User, that the domain layer must not be bothered with. It’s therefore handled in the use cases layer, and it’s handled differently depending on whether a normal user or an admin user tries to add items.
Let’s also discuss how logging is handled in this layer. In software applications, all kinds of logging takes place within several layers. While all log entries might end up in a text file on a hard drive, again it’s important to separate the technical from the conceptual details. Our use cases layer doesn’t know about text files and hard drives. Conceptually, this layer just says: “Regarding the application use cases, something interesting just happened, and I would like to have this event logged”, where “logged” does not mean “written somewhere”, it just means “logged” – without any further thought about what this actually means implementation-wise.
Thus, we just provide an interface that satisfies the needs of the use cases, and inject the actual implementation – this way we can, at any point in the future, and no matter how complex the application has become, decide to start writing our log messages into a database instead of a flat file – as long as we still satisfy the interface that its callers expect from the implementation, we don’t need to change even one line within any inner layers.
The way we’ve set up the two different order interactors here, even more niceties arise. If we would like to log admin operations into one file, and normal user operations into another one, then this is very simple. We would just have to create two different Logger implementations, both satisfying the usecases.Logger interface, and inject them into the interactors accordingly.
Another important detail in the use cases code is the Item struct. Don’t we already have one in the domain layer? Why not just return these in the Items() method? Because it’s wise to not leak domain entities into higher level layers. Entities might carry with them not only data, but also behaviour. This behaviour should only be triggered by use cases. If we don’t export our entities into upper layers in the first place, we make sure that this will always be the case. The upper layers only need dumb data structure to do their job, therefore, this is all we should serve them.
As with the domain layer, this code shows how a clean architecture helps to understand how a given software actually works: while we only need to look into the domain layer code to see what parts our business is made of and which rules it has, we only need to look into the use cases code to see all the interactions that are possible between a user and the business. We can see that this application allows customers themselves to add items to an order and list items within an order, and that administrators may add items to an order for customers. Print it out and you have an up-to-date documentation of all your use cases in the most reliable and accurate format possible.
The interfaces
At this point, everything that has to be said, code wise, about our actual business and our application use cases, is said. Let’s see what that means for the interfaces layer’s code. While all code in the respective inner layers logically belongs together, the interfaces layer consists of several parts that exist separately – therefore, we will split the code in this layer into several files.
As our shop has to be accessible through the web, let’s start with the web service:
$GOPATH/src/interfaces/webservice.go
package interfaces
import (
"fmt"
"io"
"net/http"
"strconv"
"usecases"
)
type OrderInteractor interface {
Items(userId, orderId int) ([]usecases.Item, error)
Add(userId, orderId, itemId int) error
}
type WebserviceHandler struct {
OrderInteractor OrderInteractor
}
func (handler WebserviceHandler) ShowOrder(res http.ResponseWriter, req *http.Request) {
userId, _ := strconv.Atoi(req.FormValue("userId"))
orderId, _ := strconv.Atoi(req.FormValue("orderId"))
items, _ := handler.OrderInteractor.Items(userId, orderId)
for _, item := range items {
io.WriteString(res, fmt.Sprintf("item id: %d\n", item.Id))
io.WriteString(res, fmt.Sprintf("item name: %v\n", item.Name))
io.WriteString(res, fmt.Sprintf("item value: %f\n", item.Value))
}
}
We are not going to implement all web services here, because they all look more or less the same. In a real application, adding an item to an order, and the show order use case for administration, need to be made available as web services, too, of course.
The most notable thing about what this code does is that it really doesn’t do much! Interfaces, if done right, tend to be simple, because their main task is to simply transport and translate data between layers. This is the case here. What happens here is that the code does what it takes to make the fact that an HTTP call arrived unrecognizable for the use cases layer.
Note that once again, injection is used to handle dependencies. The order interactor would be the real usecases.OrderInteractor in the production environment, but it could be mocked in the unit tests, making the web service handler testable in isolation, which means that its unit tests would only test the behaviour of the web service handler itself (“does it really use the ‘userId’ request parameter as the first parameter for the call to OrderInteractor.Items?”).
It’s worth discussing what a full fledged web service handler could look like. There is no authentication here, we just trust the userId parameter from the request to be valid – in a real world application, the web service handler would probably extract the requesting user from the session, which is transported using, e.g., cookies.
Whoa, wait, we already have customers and users, now we also have sessions and cookies? All the while these are more or less the same?
Well, only more or less, that’s the point. Each of them lives on a different conceptual level. Cookies are a very low-level mechanism, dealing with a bag of bytes in some browser’s memory and HTTP headers. Sessions are already a bit more abstract, a concept of different stateless requests belonging to one client – with cookies used to sort out the details.
Users are already quite high-level – a very abstract idea of “an identifiable person interacting with the application” – with sessions used to sort out the details. And lastly, there is the customer, an entity that is recognized in pure business terms – with users used to… well, you get the idea.
I recommend making these differences explicit rather than dealing with the pain that arises when using the same representation on different conceptual levels. Should you choose to replace the session’s transport mechanism from cookies to SSL client certificates, you only need to introduce a new library for the low-level details of these certificates to your infrastructure layer, and have to change the code in the interfaces layer that identifies sessions based on those low-level HTTP details – users and customers are not tangent to this change.
Also in your interfaces layer lives the code that creates HTML responses from data structures it receives from the use cases layer. In a real application, that’s probably done by using a templating library that lives in the infrastructure layer.
Let’s now look at the last building block of our application: persistence. We have a working business domain, we have use cases that put the domain in motion, and we have implemented an interface that allows users to access our application over the web. Now all we need to do is implement the mechanisms that store our business and application data on a hard drive, and we are ready for an IPO.
This is done by creating the concrete implementations of the abstract repository interfaces of our domain and use cases layers. This implementation belongs to the interfaces layer, because repositories are an interface between the low level world of databases on the one side and the high level world of our business on the other side – what is a stream of bytes on a hard drive on the one side must become an entity object on the other. The job of transforming the one into the other is that of a repository.
Some repository implementations might be limited, in their dependencies, to the interfaces layer and below, for example when writing pure in-memory runtime object caches, or when mocking a repository for a unit test. Most real world repositories however need to talk to an external persistence mechanism like a database, probably by using a library that handles the low level connection and query details – and which lives in the infrastructure layer of the system. Thus, as in other layers, we once again need to make sure that we do not violate the Dependency Rule.
It’s not that the repository is database-agnostic! It’s well aware of the fact that it talks to an SQL database. But it is directly concerned only with the high level, or, one could say, “logical” aspects of this conversation. Get data from this table, put data into that table. The low level, or “physical”, aspects, are out of its scope – stuff like connecting to the database daemon through the network, deciding to use a slave for reads and the master for writes, handling timeouts, and so forth, are infrastructural issues.
In other words, our repository would like to use a reasonably high level interface that hides all those nasty little infrastructural details and just talk some SQL to what appears to be a server that is just there and just works.
Let’s create such an interface in src/interfaces/repositories.go:
type DbHandler interface {
Execute(statement string)
Query(statement string) Row
}
type Row interface {
Scan(dest ...interface{})
Next() bool
}
That’s really a very limited interface, but it allows for all the operations the repositories need to perform: reading, inserting, updating and deleting rows.
In the infrastructure layer, we will implement some glue code that uses a sqlite3 library to actually talk to the database, while satisfying this interface – but first, let’s fully implement the repositories:
$GOPATH/src/interfaces/repositories.go
package interfaces
import (
"domain"
"fmt"
"usecases"
)
type DbHandler interface {
Execute(statement string)
Query(statement string) Row
}
type Row interface {
Scan(dest ...interface{})
Next() bool
}
type DbRepo struct {
dbHandlers map[string]DbHandler
dbHandler DbHandler
}
type DbUserRepo DbRepo
type DbCustomerRepo DbRepo
type DbOrderRepo DbRepo
type DbItemRepo DbRepo
func NewDbUserRepo(dbHandlers map[string]DbHandler) *DbUserRepo {
dbUserRepo := new(DbUserRepo)
dbUserRepo.dbHandlers = dbHandlers
dbUserRepo.dbHandler = dbHandlers["DbUserRepo"]
return dbUserRepo
}
func (repo *DbUserRepo) Store(user usecases.User) {
isAdmin := "no"
if user.IsAdmin {
isAdmin = "yes"
}
repo.dbHandler.Execute(fmt.Sprintf(`INSERT INTO users (id, customer_id, is_admin)
VALUES ('%d', '%d', '%v')`,
user.Id, user.Customer.Id, isAdmin))
customerRepo := NewDbCustomerRepo(repo.dbHandlers)
customerRepo.Store(user.Customer)
}
func (repo *DbUserRepo) FindById(id int) usecases.User {
row := repo.dbHandler.Query(fmt.Sprintf(`SELECT is_admin, customer_id
FROM users WHERE id = '%d' LIMIT 1`,
id))
var isAdmin string
var customerId int
row.Next()
row.Scan(&isAdmin, &customerId)
customerRepo := NewDbCustomerRepo(repo.dbHandlers)
u := usecases.User{Id: id, Customer: customerRepo.FindById(customerId)}
u.IsAdmin = false
if isAdmin == "yes" {
u.IsAdmin = true
}
return u
}
func NewDbCustomerRepo(dbHandlers map[string]DbHandler) *DbCustomerRepo {
dbCustomerRepo := new(DbCustomerRepo)
dbCustomerRepo.dbHandlers = dbHandlers
dbCustomerRepo.dbHandler = dbHandlers["DbCustomerRepo"]
return dbCustomerRepo
}
func (repo *DbCustomerRepo) Store(customer domain.Customer) {
repo.dbHandler.Execute(fmt.Sprintf(`INSERT INTO customers (id, name)
VALUES ('%d', '%v')`,
customer.Id, customer.Name))
}
func (repo *DbCustomerRepo) FindById(id int) domain.Customer {
row := repo.dbHandler.Query(fmt.Sprintf(`SELECT name FROM customers
WHERE id = '%d' LIMIT 1`,
id))
var name string
row.Next()
row.Scan(&name)
return domain.Customer{Id: id, Name: name}
}
func NewDbOrderRepo(dbHandlers map[string]DbHandler) *DbOrderRepo {
dbOrderRepo := new(DbOrderRepo)
dbOrderRepo.dbHandlers = dbHandlers
dbOrderRepo.dbHandler = dbHandlers["DbOrderRepo"]
return dbOrderRepo
}
func (repo *DbOrderRepo) Store(order domain.Order) {
repo.dbHandler.Execute(fmt.Sprintf(`INSERT INTO orders (id, customer_id)
VALUES ('%d', '%v')`,
order.Id, order.Customer.Id))
for _, item := range order.Items {
repo.dbHandler.Execute(fmt.Sprintf(`INSERT INTO items2orders (item_id, order_id)
VALUES ('%d', '%d')`,
item.Id, order.Id))
}
}
func (repo *DbOrderRepo) FindById(id int) domain.Order {
row := repo.dbHandler.Query(fmt.Sprintf(`SELECT customer_id FROM orders
WHERE id = '%d' LIMIT 1`,
id))
var customerId int
row.Next()
row.Scan(&customerId)
customerRepo := NewDbCustomerRepo(repo.dbHandlers)
order := domain.Order{Id: id, Customer: customerRepo.FindById(customerId)}
var itemId int
itemRepo := NewDbItemRepo(repo.dbHandlers)
row = repo.dbHandler.Query(fmt.Sprintf(`SELECT item_id FROM items2orders
WHERE order_id = '%d'`,
order.Id))
for row.Next() {
row.Scan(&itemId)
order.Add(itemRepo.FindById(itemId))
}
return order
}
func NewDbItemRepo(dbHandlers map[string]DbHandler) *DbItemRepo {
dbItemRepo := new(DbItemRepo)
dbItemRepo.dbHandlers = dbHandlers
dbItemRepo.dbHandler = dbHandlers["DbItemRepo"]
return dbItemRepo
}
func (repo *DbItemRepo) Store(item domain.Item) {
available := "no"
if item.Available {
available = "yes"
}
repo.dbHandler.Execute(fmt.Sprintf(`INSERT INTO items (id, name, value, available)
VALUES ('%d', '%v', '%f', '%v')`,
item.Id, item.Name, item.Value, available))
}
func (repo *DbItemRepo) FindById(id int) domain.Item {
row := repo.dbHandler.Query(fmt.Sprintf(`SELECT name, value, available
FROM items WHERE id = '%d' LIMIT 1`,
id))
var name string
var value float64
var available string
row.Next()
row.Scan(&name, &value, &available)
item := domain.Item{Id: id, Name: name, Value: value}
item.Available = false
if available == "yes" {
item.Available = true
}
return item
}
I hear you: from more than one point of view, this is terrible code! A lot of duplication, no error handling, and several other smells. But the point of this tutorial is neither code style nor design patterns – it’s all about the architecture of the application, and therefore I took the freedom to create very simplistic code that only has to be straightforward and comprehensible, not elegant and clever – oh and yes, I’m still a Go beginner, which shows.
Note the dbHandlers map in every repository – that’s here so every repository can use every other repository without giving up on Dependency Injection – if some of the repositories use a different DbHandler implementation than others, then repositories using other repositories don’t need to know who uses what; it’s kind of a poor man’s Dependency Injection Container.
Let’s dissect one of the more interesting methods, DbUserRepo.FindById(). It’s a good example to illustrate that in our architecture, interfaces really are all about transforming data from one layer to the next. FindById reads database rows and produces domain and usescases entities. I have deliberately made the database representation of the User.IsAdmin attribute more complicated than neccessary, by storing it as “yes” and “no” varchars in the database. In the usecases entity User, it’s represented as a boolean value of course. Bridging the gap of these very different representations is the job of the repository.
User entities have a Customer attribute, which in turn is a domain entity; the User repository simply uses the Customer repository to retrieve the entity it needs.
It’s easy to imagine how our architecture can help us when the application grows. By following the Dependency Rule, we will be able to rework the details of entity persistence without the need to touch the entities themselves. We might decide to split the data of the User entities into multiple tables – the repository will have to sort out the details of putting together a single entity from multiple tables, but the clients of the repositories won’t be concerned.
The infrastructure
As stated above, our repositories view “The Database” as an abstract being where SQL queries can be send to and rows can be retrieved from. They don’t care about infrastructural issues like connecting to the database or even figuring out which database to use. This is done in src/infrastructure/sqlitehandler.go, where the high level DbHandler interface is implemented using low level means:
$GOPATH/src/infrastructure/sqlitehandler.go
package infrastructure
import (
"database/sql"
"fmt"
_ "github.com/mattn/go-sqlite3"
"interfaces"
)
type SqliteHandler struct {
Conn *sql.DB
}
func (handler *SqliteHandler) Execute(statement string) {
handler.Conn.Exec(statement)
}
func (handler *SqliteHandler) Query(statement string) interfaces.Row {
rows, err := handler.Conn.Query(statement)
if err != nil {
fmt.Println(err)
return new(SqliteRow)
}
row := new(SqliteRow)
row.Rows = rows
return row
}
type SqliteRow struct {
Rows *sql.Rows
}
func (r SqliteRow) Scan(dest ...interface{}) {
r.Rows.Scan(dest...)
}
func (r SqliteRow) Next() bool {
return r.Rows.Next()
}
func NewSqliteHandler(dbfileName string) *SqliteHandler {
conn, _ := sql.Open("sqlite3", dbfileName)
sqliteHandler := new(SqliteHandler)
sqliteHandler.Conn = conn
return sqliteHandler
}
(Again, zero error handling, among other things, in order to keep out code that doesn’t contribute to the architectural ideas).
Using Yasuhiro Matsumoto’s sqlite3 library, this infrastructure code implements the DbHandler interface that allows the repositories to talk to the database without the need to fiddle with low level details.
Putting it all together
That’s it, all our architectural building blocks are now in place – let’s put them together in main.go:
$GOPATH/main.go
package main
import (
"usecases"
"interfaces"
"infrastructure"
"net/http"
)
func main() {
dbHandler := infrastructure.NewSqliteHandler("/var/tmp/production.sqlite")
handlers := make(map[string] interfaces.DbHandler)
handlers["DbUserRepo"] = dbHandler
handlers["DbCustomerRepo"] = dbHandler
handlers["DbItemRepo"] = dbHandler
handlers["DbOrderRepo"] = dbHandler
orderInteractor := new(usecases.OrderInteractor)
orderInteractor.UserRepository = interfaces.NewDbUserRepo(handlers)
orderInteractor.ItemRepository = interfaces.NewDbItemRepo(handlers)
orderInteractor.OrderRepository = interfaces.NewDbOrderRepo(handlers)
webserviceHandler := interfaces.WebserviceHandler{}
webserviceHandler.OrderInteractor = orderInteractor
http.HandleFunc("/orders", func(res http.ResponseWriter, req *http.Request) {
webserviceHandler.ShowOrder(res, req)
})
http.ListenAndServe(":8080", nil)
}
Due to our quite excessive use of dependency injection, some construction work is necessary before the building blocks of our application can start moving. Our repositories must be injected with a DbHandler implementation, and in turn, they are injected into the use case interactor. The interactor gets injected into the webservice handler, which is then set up to server a specific route. At last, the http server starts.
Boxes in boxes in boxes, and every single one can be exchanged with something that works completely different under the hood – as long as it serves the same API, it will work.
We can use the following SQL to create a minimal data set in /var/tmp/production.sqlite:
CREATE TABLE users (id INTEGER, customer_id INTEGER, is_admin VARCHAR(3));
CREATE TABLE customers (id INTEGER, name VARCHAR(42));
CREATE TABLE orders (id INTEGER, customer_id INTEGER);
CREATE TABLE items (id INTEGER, name VARCHAR(42), value FLOAT, available VARCHAR(3));
CREATE TABLE items2orders (item_id INTEGER, order_id INTEGER);
INSERT INTO users (id, customer_id, is_admin) VALUES (40, 50, "yes");
INSERT INTO customers (id, name) VALUES (50, "John Doe");
INSERT INTO orders (id, customer_id) VALUES (60, 50);
INSERT INTO items (id, name, value, available) VALUES (101, "Soap", 4.99, "yes");
INSERT INTO items (id, name, value, available) VALUES (102, "Fork", 2.99, "yes");
INSERT INTO items (id, name, value, available) VALUES (103, "Bottle", 6.99, "no");
INSERT INTO items (id, name, value, available) VALUES (104, "Chair", 43.00, "yes");
INSERT INTO items2orders (item_id, order_id) VALUES (101, 60);
INSERT INTO items2orders (item_id, order_id) VALUES (104, 60);
Now, we can start the application, and point our browser at http://localhost:8080/orders?userId=40&orderId=60. The result should be:
item id: 101
item name: Soap
item value: 4.990000
item id: 104
item name: Chair
item value: 43.000000
And with this, it’s time to pat ourselves on the shoulder.
Afterthoughts
Which doesn’t mean that the application can’t be further improved. For example, repositories using other repositories is currently limited because all repositories must be DbHandler repositories; should we decide to store items in a MongoDB while keeping orders in a relational SQL database, then our DbOrderRepo can’t create the DbItemRepo the way it does; the solution would be to create a registry or dependency injection container that provides the full repositories, not only the db handlers.
However, we have created an architecture that allows such changes easily. Only very specific parts of the applications would need to be changed, without risking to break use cases or domain logic. Which is the beauty that is The Clean Architecture.
Update 2016-01-15
Blog reader Eduard Sesigin has created a visualization that shows how the different files and their code are distributed over the architectural layers, and how they are related to each other:
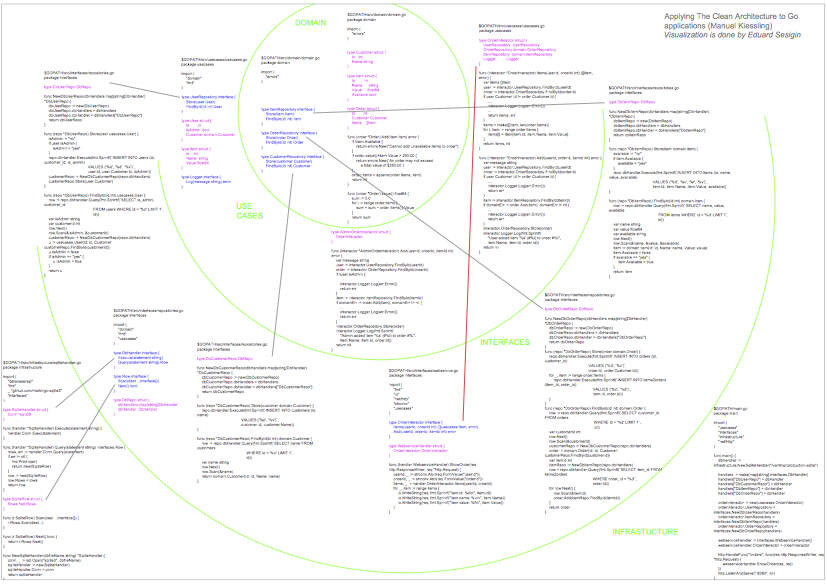
Click on the image to open a high resolution PDF version.
Russian translation
There is also a russian translation of this post over at https://habrahabr.ru/post/269893/.
По адресу https://habrahabr.ru/post/269893/ находится русский перевод этой статьи.
Acknowledgements
This tutorial would not exist if “Uncle” Bob Martin wouldn’t restlessly teach us how to do software development and software architecture.
Many people from the golang-nuts mailing list gave valuable feedback, among them, in no particular order: Gheorghe Postelnicu, Hannes Baldursson, Francesc Campoy Flores, Christoph Hack, Gaurav Garg, Paddy Foran, Sanjay Menakuru, Larry Clapp, Steven Degutis, Sanjay, Jesse McNelis, Mateusz Czapliński, and Rob Pike. Jon Jagger has again been a critical and helpful mentor.