Tutorial: Single Page Applications with a Serverless Backend and Infrastructure as Code
About
From zero to production: this extensive guide describes in detail how to create and deploy a React-based web app frontend using TypeScript and Redux Toolkit on top of a Node.js based AWS Lambda backend with a DynamoDB database, connect and integrate them through API Gateway and CloudFront, and explains how to codify and automate the required cloud infrastructure and deployment process using Terraform.
Background
One of my current tasks at Joboo.de is to define an architecture and tech stack for our most complex web UIs, an area where our existing MariaDB + Symfony + jQuery solution just won’t cut it.
In order to experiment in a wholesome way, I used this as an excuse to finally build my first software-and-systems side project that is 100% serverless on the backend and 100% an SPA on the frontend.
After all, that’s how all great software projects start: with CV Driven Development!
As if that wasn’t enough, I’m also the guy with this tweet:
Never underestimate how far web apps with Server-Side Page Rendering that do Full Page Reloads On Every Click powered by a One Thread Per Request Language running as a Monolithic Service On A Non-Distributed System can get you in terms of generating real value for real customers.
Now, I wouldn’t say that what I wrote back then was wrong (who am I to criticize people on Twitter?), but let’s say that I’m well aware of the limitations of my year-long go-to stack described above.
This shows how part of my approach was driven by a “know your enemy” attitude: I have no problem disliking something passionately, but I really don’t want to dislike it for the wrong reasons or because I’m not well-informed enough.
I was sure that there are plenty of very valid reasons to use an SPA + serverless architecture, and I wanted to finally embrace it for good, making it part of my toolbox.
There are two results of this journey. The first one is LogBuddy.io, which we now use at Joboo.de for some of our more simple logging use cases, where something like an ELK stack setup is overkill.
The second one is this tutorial - it is based on a bare-minimum implementation of the LogBuddy architecture and tech stack, and as such describes a target setup for a very simple but also fully-functional web app. The tutorial guides you through all steps required to have this setup up and running in your own AWS account, from zero to production.
The project
When all steps of this tutorial have been followed, the result is a very simple note-keeping app on Amazon Web Services implemented as a React/Redux web frontend served via CloudFront (in front of S3) that talks to a Node.js backend running on Lambda which, too, is served via CloudFront (in front of API Gateway), with data written to and read from a DynamoDB table.
A complete and fully working code base for this setup is available on GitHub. However, some notes regarding this code base:
- It’s much better to follow the step-by-step tutorial below than to only check out the finished result.
- The code base represents what I consider a best-practice approach for the given target architecture; however, in order to ensure a level of brevity required for a concise tutorial that doesn’t overwhelm its readers, it is not a best-practice implementation down to the last detail! For example, it is lacking software tests, which is a no-go for any serious software project.
The bottom line is this: take the ideas and use what you learn from this tutorial and its final code base, but do not simply take the code base as the foundation of your next web app project.
Prerequisites
In order to follow along, you will need the following:
A macOS or Linux system
While it’s certainly possible to develop the required code base on a Microsoft Windows system, my resources only allow to ensure that the tutorial and its result will work on a Unix-like operating system.
Note that we are going to do a lot of work on the command line, so make sure that you have a terminal application available.
An Amazon AWS account
A simple personal account is perfectly fine, but for the sake of simplicity you need full access to all resources in this account (i.e., an AWS account root user or an IAM user attached to the “AdministratorAccess” policy). Create a new account at aws.amazon.com if necessary, or use an existing one.
This, of course, isn’t the best practice approach when working with AWS, but the best-practice approach would go beyond the scope of this tutorial. See my Single Sign-On and Resource Separation on AWS guide for more information on this topic.
While not all resources that need to be created fall under the AWS Free Tier offering, AWS costs will be minimal to non-existent - after all, that’s exactly the idea when building a serverless project that doesn’t receive any relevant amount of traffic. And thanks to the Infrastructure as Code approach of the tutorial, everything we deploy can be torn down and removed with a single command.
However, all of this still means that ultimately, you alone are responsible for managing and monitoring your AWS costs.
AWS Command Line Interface version 2
If you do not yet have the AWS CLI installed on your system, then please refer to the official Installing, updating, and uninstalling the AWS CLI version 2 guide.
In case you are working on a macOS system that uses Homebrew, it’s as simple as brew install awscli.
Terraform
During this tutorial, we will create a small but full-fledged SPA + serverless infrastructure on AWS, but we are not going to do this manually through the web-based AWS console. Instead, our infrastructure will be defined with HashiCorp Configuration Language (HCL) code files. These code files are then read and interpreted via Terraform; this tool talks to AWS and does the actual heavy lifting of getting our infrastructure deployed.
This approach is called “Infrastructure as Code”. If you are new to this concept, feel free to head over to my Healthy Continuous Delivery: Infrastructure-as-Code guide first.
Don’t worry though - I will explain everything Terraform-related in detail below.
Just make sure to install the most recent version of the Terraform CLI command for your platform, available at https://www.terraform.io/downloads.html.
Node Version Manager - NVM
To ensure that you have just the right version of Node.js and NPM, you need to have NVM installed on your machine. The official NVM installation guide has all the details.
Preparation
As a final check that everything we will need is available and working, make sure that running aws --version, terraform -version, and nvm --version on your command line all look good.
If these look encouraging, we can start by setting up the AWS credentials on the local system. This allows AWS CLI and Terraform to talk to AWS.
Log into your AWS account on https://console.aws.amazon.com, and afterwards, head over to “My Security Credentials” at https://console.aws.amazon.com/iam/home#/security_credentials.
Under the “Access keys for CLI, SDK, & API access” headline, hit the “Create access key” button. This gives you an Access key ID and a Secret access key. Keep the page open in order to copy-and-paste these in the next step.
Open your terminal application, run aws configure, and paste the key ID and secret access key, like this:
> aws configure
AWS Access Key ID [****************]: AKIAUCFPZVBYGKDEGPNF
AWS Secret Access Key [****************]: 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
Default region name []: us-east-1
Default output format []: text
Make sure to set the default region to us-east-1 and the output format to text.
The infrastructure: Automating AWS resource management with Terraform
We can now start to build our AWS infrastructure. To do so, create a project directory and open it in your favourite programming editor or IDE.
Within the project folder, create a subfolder infrastructure, and in this subfolder, create file main.tf.
Put the following HCL code into this file:
provider "aws" {
region = "us-east-1"
}
This tells Terraform that we want it to be able to talk to AWS in region “us-east-1”.
Next, create file variables.tf with this content:
variable "project_name" {
type = string
default = "PLEASE-CHANGE-ME"
}
variable "deployment_number" {
type = string
default = "initial"
}
While an AWS account is mostly an isolated thing, some resources like S3 bucket names must be globally unique. Therefore, our project needs its own, unique name which we can then use when naming these kinds of resources.
This means that you MUST change the PLEASE-CHANGE-ME part of this file into something that is guaranteed to be unique; for example, your name and something weird, like default = "john-doe-frumbazel".
The deployment_number variable will be explained later.
At this point, we can run Terraform for the first time, in order to initialize the project. It should look like this:
> terraform init
Initializing the backend...
Initializing provider plugins...
- Finding latest version of hashicorp/aws...
- Installing hashicorp/aws v3.37.0...
- Installed hashicorp/aws v3.37.0 (signed by HashiCorp)
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
S3: A place in the cloud for our code
With this, Terraform is prepared to do some real work, so let’s give it something to work on. We start by defining our S3 setup, in file s3.tf:
resource "aws_s3_bucket" "frontend" {
bucket = "${var.project_name}-frontend"
force_destroy = "false"
website {
index_document = "index.html"
error_document = "error.html"
}
acl = "public-read"
}
resource "aws_s3_bucket_public_access_block" "frontend" {
bucket = aws_s3_bucket.frontend.id
block_public_acls = false
block_public_policy = false
ignore_public_acls = false
restrict_public_buckets = false
}
resource "aws_s3_bucket" "backend" {
bucket = "${var.project_name}-backend"
force_destroy = "false"
acl = "private"
}
resource "aws_s3_bucket_public_access_block" "backend" {
bucket = aws_s3_bucket.backend.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
Our application will have a frontend (React) and a backend (Node.js), and the code for these needs to be made available to the user’s browser (frontend) and to AWS Lambda (backend). This is achieved by putting the code into an S3 bucket, one for the frontend code and one for the backend code.
We therefore define these buckets with Terraform, using the resource statement aws_s3_bucket. As said, each bucket needs to have a globally unique name, which is why we prepend our unique project_name variable to their names.
An additional resource, aws_s3_bucket_public_access_block, ensures that the frontend code is accessible from the outside (CloudFront will need to access the files in order to serve them to the user’s browser), while the backend code should be treated as confidential, and any public access will be denied. Internally, AWS Lambda will still be able to load these code files.
Well, simply declaring these resources in a Terraform file doesn’t create them, so let’s do this now by running terraform apply:
> terraform apply
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# aws_s3_bucket.backend will be created
# aws_s3_bucket.frontend will be created
# aws_s3_bucket_public_access_block.backend will be created
# aws_s3_bucket_public_access_block.frontend will be created
Plan: 4 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
aws_s3_bucket.backend: Creating...
aws_s3_bucket.frontend: Creating...
aws_s3_bucket.backend: Creation complete after 8s [id=efiuheruk-backend]
aws_s3_bucket_public_access_block.backend: Creating...
aws_s3_bucket.frontend: Creation complete after 9s [id=efiuheruk-frontend]
aws_s3_bucket_public_access_block.frontend: Creating...
aws_s3_bucket_public_access_block.backend: Creation complete after 1s [id=efiuheruk-backend]
aws_s3_bucket_public_access_block.frontend: Creation complete after 1s [id=efiuheruk-frontend]
Apply complete! Resources: 4 added, 0 changed, 0 destroyed.
Note that I have removed a lot of lines from the actual output to make it more readable.
DynamoDB: Persistent state for the backend
Next up is DynamoDB. We will use this simple AWS NoSQL database for storing the data of our application, namely the “notes” that the application allows its users to create.
We only need a single table, and the Terraform code for this (which belongs in file dynamodb.tf) is straightforward:
resource "aws_dynamodb_table" "notes" {
name = "notes"
billing_mode = "PROVISIONED"
read_capacity = 1
write_capacity = 1
hash_key = "id"
attribute {
name = "id"
type = "S"
}
}
At this point we have a place for our frontend and backend code files, and a database table where the backend can store its data.
Lambda: Running Node.js code without a server
Our backend code is supposed to run on AWS Lambda, and we can now define the Lambda function for this. To do so, create file lambda.tf with the following content:
resource "aws_lambda_function" "rest_api" {
function_name = "rest_api"
s3_bucket = aws_s3_bucket.backend.bucket
s3_key = "${var.deployment_number}/rest_api.zip"
handler = "index.handler"
runtime = "nodejs14.x"
role = aws_iam_role.lambda_rest_api.arn
}
Every Lambda function assumes an AWS IAM Role when running, which gives the function an identity within the AWS user and access management system that can be used to determine what access rights the function has during its run time. This is important whenever Lambda function codes needs to talk to other AWS resources, like our DynamoDB database table.
In the HCL code above, we refer to this role on the last line. Let’s make sure that this role exists by adding the following code to file lambda.tf:
resource "aws_iam_role" "lambda_rest_api" {
name = "lambda_rest_api"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}
The role itself is just an empty hull that gives our Lambda an identity, and does not, by itself, define any access rights. This is achieved by attaching IAM policies to the role. First and foremost, we need to attach a predefined policy which provides the most basic access rights that every Lambda function needs to work at all. This is achieved with the following definition:
data "aws_iam_policy" "AWSLambdaBasicExecutionRole" {
arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}
resource "aws_iam_role_policy_attachment" "AWSLambdaBasicExecutionRole_to_lambda_rest_api" {
policy_arn = data.aws_iam_policy.AWSLambdaBasicExecutionRole.arn
role = aws_iam_role.lambda_rest_api.name
}
The code above references the existing policy using an HCL data block, which creates a references that can be used in the aws_iam_role_policy_attachment resource block, attaching the policy to the role.
We also need to create and attach our own policy, which defines the access rights that will allow the Lambda function to operate on the DynamoDB table we have created earlier:
resource "aws_iam_policy" "dynamodb_default" {
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"dynamodb:PutItem",
"dynamodb:GetItem",
"dynamodb:Query",
"dynamodb:GetRecords",
"dynamodb:Scan"
],
"Resource": [
"${aws_dynamodb_table.notes.arn}"
]
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "dynamodb_default_to_lambda_rest_api" {
policy_arn = aws_iam_policy.dynamodb_default.arn
role = aws_iam_role.lambda_rest_api.name
}
At this point, we have a problem. On line 5 of file lambda.tf, we refer to a ZIP file within our backend S3 bucket:
s3_key = "${var.deployment_number}/rest_api.zip"
As you can see, this makes use of the deployment_number variable we defined earlier - it will allow us to easily deploy backend code changes later on.
The problem right now is that there is no file rest_api.zip at this location, and AWS would therefore not be able to apply our Terraform code.
It won’t be a problem later when our backend code base exists - but for the moment, we need to fake that, by creating a dummy ZIP file and placing it at the referenced location manually, like so:
> zip rest_api.zip main.tf
adding: main.tf (stored 0%)
> aws s3 cp rest_api.zip s3://PLEASE-CHANGE-ME-backend/initial/rest_api.zip
upload: ./rest_api.zip to s3://PLEASE-CHANGE-ME-backend/initial/rest_api.zip
> rm rest_api.zip
Of course, you need to change the PLEASE-CHANGE-ME part the same way you changed it in file variables.tf, in order to end up with the correct S3 bucket name.
Once this is done, you are able to successfully start another run of terraform apply and set up the Lambda function.
Afterwards, our Lambda function exists, but it exists in isolation, and cannot be triggered from the outside. We therefore need to connect it to an AWS resource which is able to trigger it. In our case, the Lambda function will wrap our backend REST API implementation, and therefore, it should be triggered whenever our frontend code makes an HTTP request to the API.
API Gateway: Connecting Lambda to the outer world
On AWS, HTTP calls can trigger Lambda functions by making an HTTP endpoint available through API Gateway. The Terraform HCL code for this, in file api-gateway.tf, looks like this:
resource "aws_apigatewayv2_api" "default" {
name = "default-api"
protocol_type = "HTTP"
}
resource "aws_apigatewayv2_stage" "default_api" {
api_id = aws_apigatewayv2_api.default.id
name = "api"
auto_deploy = true
default_route_settings {
throttling_burst_limit = 10
throttling_rate_limit = 10
}
}
resource "aws_apigatewayv2_integration" "lambda_rest_api" {
api_id = aws_apigatewayv2_api.default.id
integration_type = "AWS_PROXY"
integration_method = "POST"
integration_uri = aws_lambda_function.rest_api.invoke_arn
}
resource "aws_apigatewayv2_route" "proxy" {
api_id = aws_apigatewayv2_api.default.id
route_key = "ANY /{proxy+}"
target = "integrations/${aws_apigatewayv2_integration.lambda_rest_api.id}"
}
resource "aws_lambda_permission" "rest_api" {
statement_id = "AllowAPIGatewayInvoke"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.rest_api.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.default.execution_arn}/*/*"
}
This defines a very simple API Gateway setup, where every HTTP request is always forwarded to our Lambda function without further ado. We also define an API Gateway stage named “api” - we do this to make the API Gateway setup handle HTTP requests that are targeted at the /api path of the API address. This way, we can serve our frontend at / and the API at /api of the same domain (CloudFront will take care of that in a moment), and thus, we don’t need to separate frontend and backend over two different domains.
This spares us from building a more complicated setup where the frontend at https://foo.com will request the API at https://bar.com, which would require a relatively involved CORS setup.
We also need to allow API Gateway to access our Lambda function - the aws_lambda_permission resource takes care of that.
At this point, you can run terraform apply again.
CloudFront: Integrating everything
We have now reached the final step of defining and building the infrastructure. What’s left is to integrate all the parts from the browser’s perspective - we need a web address and a system which serves both the frontend code and the API endpoint at this address, again in a serverless way (meaning we don’t want to build our own VM with Nginx or Apache, for example). AWS CloudFront is the obvious choice for this - it will act as a reverse proxy in front of both API Gateway and S3.
This is achieved by the following Terraform definitions, in file cloudfront.tf:
resource "aws_cloudfront_distribution" "default" {
enabled = true
price_class = "PriceClass_All"
origin {
domain_name = "${aws_s3_bucket.frontend.id}.s3-website-${aws_s3_bucket.frontend.region}.amazonaws.com"
origin_id = "s3-${aws_s3_bucket.frontend.id}"
custom_origin_config {
http_port = 80
https_port = 443
origin_keepalive_timeout = 5
origin_protocol_policy = "http-only"
origin_read_timeout = 30
origin_ssl_protocols = ["TLSv1.2"]
}
}
default_cache_behavior {
allowed_methods = ["GET", "HEAD", "OPTIONS"]
cached_methods = ["GET", "HEAD", "OPTIONS"]
target_origin_id = "s3-${aws_s3_bucket.frontend.id}"
viewer_protocol_policy = "redirect-to-https"
compress = true
forwarded_values {
query_string = true
cookies {
forward = "all"
}
headers = ["Access-Control-Request-Headers", "Access-Control-Request-Method", "Origin"]
}
}
origin {
domain_name = replace(
replace(
aws_apigatewayv2_stage.default_api.invoke_url,
"https://",
""
),
"/api",
""
)
origin_id = "api-gateway-default"
custom_origin_config {
http_port = 80
https_port = 443
origin_protocol_policy = "https-only"
origin_ssl_protocols = ["TLSv1.2"]
}
}
ordered_cache_behavior {
allowed_methods = ["GET", "HEAD", "OPTIONS", "POST", "PUT", "DELETE", "PATCH"]
cached_methods = ["GET", "HEAD", "OPTIONS"]
path_pattern = "api*"
target_origin_id = "api-gateway-default"
viewer_protocol_policy = "https-only"
cache_policy_id = aws_cloudfront_cache_policy.api_gateway_optimized.id
origin_request_policy_id = aws_cloudfront_origin_request_policy.api_gateway_optimized.id
}
restrictions {
geo_restriction {
restriction_type = "none"
}
}
viewer_certificate {
cloudfront_default_certificate = true
}
is_ipv6_enabled = true
}
resource "aws_cloudfront_cache_policy" "api_gateway_optimized" {
name = "ApiGatewayOptimized"
default_ttl = 0
max_ttl = 0
min_ttl = 0
parameters_in_cache_key_and_forwarded_to_origin {
cookies_config {
cookie_behavior = "none"
}
headers_config {
header_behavior = "none"
}
query_strings_config {
query_string_behavior = "none"
}
}
}
resource "aws_cloudfront_origin_request_policy" "api_gateway_optimized" {
name = "ApiGatewayOptimized"
cookies_config {
cookie_behavior = "none"
}
headers_config {
header_behavior = "whitelist"
headers {
items = ["Accept-Charset", "Accept", "User-Agent", "Referer"]
}
}
query_strings_config {
query_string_behavior = "all"
}
}
As you can see, two origins are defined, one pointing at the “frontend” S3 bucket, and the other at the Lambda function’s invoke URL. By adding an ordered cache behavior, we can direct every request beginning with /api at the Lambda origin, while everything else is served from the S3 bucket.
After running terraform apply once again, our infrastructure is complete. Note that creating the CloudFront distribution may take several minutes.
But “where” is our infrastructure? We didn’t define our own domain name - but every CloudFront distribution comes with it’s own domain name ending on .cloudfront.net.
To see this domain name, we can use Terraform’s output capability. Simply create a file named outputs.tf, with the following content:
output "cloudfront_domain_name" {
value = aws_cloudfront_distribution.default.domain_name
}
Then, run terraform refresh, and the result will look like this:
> terraform refresh
aws_dynamodb_table.notes: Refreshing state... [id=notes]
aws_cloudfront_origin_request_policy.api_gateway_optimized: Refreshing state... [id=c53def6c-7e89-4104-bc93-7ad928c0da16]
aws_apigatewayv2_api.default: Refreshing state... [id=yp1vyzyv18]
(...truncated more lines like this...)
Outputs:
cloudfront_domain_name = "d1ka2fzxbv1rta.cloudfront.net"
Note that the first part of the domain name will of course be different in your case.
You can already open this domain in your browser, but you will be greeted with a “404 Not Found” error message. The way we defined the infrastructure, opening http://d1ka2fzxbv1rta.cloudfront.net/ will first result in a redirect to https://d1ka2fzxbv1rta.cloudfront.net (see file cloudfront.tf, line 63, viewer_protocol_policy = "redirect-to-https"), and then CloudFront will try to serve file index.html from the frontend S3 bucket. This file does not yet exist, and will be created only late in the process when we build and upload our React app for the first time.
We will first create and deploy the backend code for the REST API served at https://d1ka2fzxbv1rta.cloudfront.net/api, though.
The backend: Building a REST API on AWS Lambda
To do so, create a new folder backend within the project folder, on the same level as folder infrastructure. This is going to be a Node.js project, so we start by adding a .nvmrc file and switching to the defined Node.js version with NVM:
> echo "14" > .nvmrc
> nvm install
Found '/Users/manuelkiessling/rtla/backend/.nvmrc' with version <14>
v14.16.1 is already installed.
Now using node v14.16.1 (npm v6.14.12)
We use version 14 of Node.js because at the time of this writing, that’s the most recent version of Node.js supported by AWS Lambda. We’ve defined that we want to use this in file infrastructure/lambda.tf on line 8: runtime = "nodejs14.x".
Creating a package.json
It’s now time to initialize the backend project via NPM:
> npm init
package name: (backend)
version: (1.0.0)
description:
entry point: (index.js) src/index.ts
test command:
git repository:
keywords:
author:
license: (ISC) UNLICENSED
About to write to /Users/manuelkiessling/rtla/backend/package.json:
{
"name": "backend",
"version": "1.0.0",
"description": "",
"main": "src/index.ts",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "UNLICENSED"
}
Is this OK? (yes) yes
Installing the dependencies
As we are going to write our backend code as a Node.js project for the AWS platform using TypeScript, we need a handful of dependencies, namely TypeScript, the AWS JavaScript SDK, and TypeScript type definitions for Node.js and the AWS SDK:
> npm install typescript aws-sdk @types/aws-lambda @types/node --target_arch=x64 --target_platform=linux --target_libc=glibc --save
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN backend@1.0.0 No description
npm WARN backend@1.0.0 No repository field.
+ typescript@4.2.4
+ @types/node@14.14.41
+ aws-sdk@2.892.0
+ @types/aws-lambda@8.10.75
added 17 packages from 146 contributors and audited 17 packages in 1.962s
1 package is looking for funding
run `npm fund` for details
found 0 vulnerabilities
Note the --target arguments when running npm install. These are crucial whenever we work on Node.js projects for AWS Lambda. Upon installation, some NPM packages pull in (or compile) binary extensions that extend their JavaScript code. These are architecture-specific, and thus different files are pulled in when running npm install on a macOS system versus a Linux system, for example. But AWS Lambda is a Linux-based Node.js environment that wouldn’t know how to handle binary files for a macOS system. Thus, we force NPM to always install dependencies for a glibc-based x64 Linux environment.
A first implementation
Next, create file src/index.ts, with a bare minimum implementation that will output the event data which API Gateway passes to our Lambda function upon invocation:
import { APIGatewayProxyHandler } from 'aws-lambda';
export const handler: APIGatewayProxyHandler = async (event) => {
return {
statusCode: 200,
body: JSON.stringify(event, null, 2),
};
}
This shows how Lambda is designed: AWS services like API Gateway can invoke a piece of code, the Lambda function, whenever a defined event occurs. In case of API Gateway, such an event typically occurs whenever an HTTP request is sent to an API Gateway endpoint. API Gateway takes the request data and wraps it into an event object, which is then passed as the first parameter to a function exported under the name handler by the Lambda code.
The Lambda handler code can then operate on this event data, and is expected to return a value that is usable for the invoking AWS service; as API Gateway needs to return an HTTP response to the client which requested its endpoint, the Lambda code needs to return an object containing at least an HTTP status code and an HTTP body.
Setting up TypeScript compilation
We now need to get this code into AWS Lambda. The first step is to transpile it from TypeScript into JavaScript, as Lambda provides a Node.js runtime that can only execute JavaScript code.
For this, we can use the tsc compiler that ships with TypeScript. It needs a configuration file tsconfig.json in folder backend to correctly transpile our TypeScript code:
{
"compilerOptions": {
"outDir": "./build",
"target": "es5",
"lib": [
"esnext",
"dom"
],
"allowJs": true,
"skipLibCheck": true,
"esModuleInterop": true,
"allowSyntheticDefaultImports": true,
"strict": true,
"forceConsistentCasingInFileNames": true,
"noFallthroughCasesInSwitch": true,
"module": "commonjs",
"moduleResolution": "node",
"resolveJsonModule": true,
"isolatedModules": true,
"noEmit": false,
},
"include": ["src/**/*"],
"exclude": ["node_modules"],
}
With this file in place, run the following command from folder backend:
> ./node_modules/.bin/tsc --build tsconfig.json
This will create file build/index.js. As we need to provide a ZIP file for AWS Lambda, let’s create it as follows:
> cd build
> zip rest_api.zip index.js
adding: index.js (deflated 62%)
We can now upload this file to S3 - however, it’s not enough to simply replace the existing fake ZIP file. Instead, we need to put it into a new subfolder within the S3 bucket, and need to point the Lambda setup at this new file.
A first manual deployment
To do so, let’s first upload the file to a new subfolder:
> aws s3 cp rest_api.zip s3://PLEASE-REPLACE-ME-backend/version-1/rest_api.zip
upload: ./rest_api.zip to s3://PLEASE-REPLACE-ME-backend/version-1/rest_api.zip
And then, switch to folder infrastructure, and update the setup as follows:
> terraform apply -var deployment_number="version-1"
Testing the endpoint
At this point, we have for the first time a working API-Gateway-plus-Lambda setup, which can be verified as follows (don’t forget to use your CloudFront domain name):
> curl https://d1ka2fzxbv1rta.cloudfront.net/api/
{
"version": "1.0",
"resource": "/{proxy+}",
"path": "/api/",
"httpMethod": "GET",
"headers": {
"Content-Length": "0",
"Host": "ei64mptro7.execute-api.us-east-1.amazonaws.com",
...many more headers...
},
"multiValueHeaders": {
...
},
"queryStringParameters": null,
"multiValueQueryStringParameters": null,
"requestContext": {
...
},
"path": "/api/",
...
},
"pathParameters": {
"proxy": ""
},
"stageVariables": null,
"body": null,
"isBase64Encoded": false
}
As expected, any HTTP request to the /api path echoes back the event object that API Gateway passed as the first parameter when invoking our Lambda handler function.
Automating the deployment
Let’s streamline this deployment process a bit. First, in file backend/package.json, add an NPM script definition as follows:
"scripts": {
"build": "rm -rf build && tsc --build tsconfig.json"
}
Then, write a helper script in file bin/deploy.sh with the following content:
#!/usr/bin/env bash
set -e
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )"
DEPLOYMENT_NUMBER="$(date -u +%FT%TZ)"
echo "$DEPLOYMENT_NUMBER" > "$DIR/../deployment_number"
PROJECT_NAME="$(cat "$DIR/../infrastructure/variables.tf" | grep 'project_name' -A 2 | grep 'default' | cut -d '=' -f 2 | cut -d '"' -f 2)"
pushd "$DIR/../backend/"
npm run build
pushd build
zip -r rest_api.zip ./
aws s3 cp ./rest_api.zip "s3://$PROJECT_NAME-backend/$DEPLOYMENT_NUMBER/"
popd
popd
pushd "$DIR/../infrastructure"
terraform apply -auto-approve -var deployment_number="$DEPLOYMENT_NUMBER"
popd
This automates the process of creating a new deployment-number value on each run, retrieves the project name from file infrastructure/variables.tf, and then runs through the steps of building and uploading a new backend code build. Last but not least, it runs Terraform to make sure that the Lambda function is set up with the newly uploaded backend code.
So from here on, just run bash bin/deploy.sh whenever you want to update the backend.
With this automation in place, we can now start working on the actual REST API implementation.
Implementing API endpoints
The API needs to provide two endpoints - one where we can send the data of a newly created note to, in order to have it persisted in the database (via POST /api/notes/), and one where we can retrieve all notes that have been persisted in the database so far (via GET /api/notes/).
Let’s head back to file backend/src/index.ts and start with note creation via POST. First, we need to set up the AWS SDK and create a client to speak to DynamoDB:
import { APIGatewayProxyEvent, APIGatewayProxyHandler } from 'aws-lambda';
import { AWSError } from 'aws-sdk';
const AWS = require('aws-sdk');
AWS.config.update({ region: 'us-east-1' });
const docClient = new AWS.DynamoDB.DocumentClient();
export const handler: APIGatewayProxyHandler = async (event) => {
return {
statusCode: 200,
body: JSON.stringify(event, null, 2),
};
}
Next, we add a function that takes the event object and handles it by creating and persisting a new “note” table entry in our database:
const handleCreateNoteRequest = async (event: APIGatewayProxyEvent) => {
let requestBodyJson = '';
{
if (event.isBase64Encoded) {
requestBodyJson = (Buffer.from(event.body ?? '', 'base64')).toString('utf8');
} else {
requestBodyJson = event.body ?? '';
}
}
const requestBodyObject = JSON.parse(requestBodyJson) as { id: string, content: string };
await new Promise((resolve, reject) => {
docClient.put(
{
TableName: 'notes',
Item: {
id: requestBodyObject.id,
content: requestBodyObject.content
}
},
(err: AWSError) => {
if (err) {
console.error(err);
reject(err);
} else {
resolve(null);
}
});
});
return {
statusCode: 201,
headers: {
'content-type': 'text/plain'
},
body: 'Created.',
};
};
The function starts by checking the value of attribute event.isBase64Encoded - the request body content that API Gateway passes on to Lambda normally is base64 encoded, but we can’t take that for granted. Therefore, we need to handle both cases, and transform the content if needed.
With this out of the way, we can transform the request body into a JSON object. We use TypeScript to define what form of object we expect.
Again, this tutorial’s code is not meant as a template for a battle-tested production-ready application; we omit, among other things, extensive validation of the data we receive, because a) we know what kind of data our yet-to-be-written frontend app will send to the API, and because b), more than anything else, I want to keep the code here as short as possible.
Next, we will await a Promise which wraps the call to the put function of the DynamoDB docClient we created earlier. This will insert a new entry into the “notes” table, with an id attribute and a content attribute.
We can now integrate this function into our Lambda code, by extending the existing handler function with some logic that identifies the kind of API call that has been made (by looking at the combination of HTTP verb used plus the requested path, which from API Gateway’s perspective is a path parameter for the catch-all route defined on line 27 of file infrastructure/api-gateway.tf):
export const handler: APIGatewayProxyHandler = async (event) => {
console.log('Received event', event);
const routeKey = `${event.httpMethod} ${event.pathParameters?.proxy}`;
if (routeKey === 'POST notes/') {
return handleCreateNoteRequest(event);
}
return {
statusCode: 404,
body: `No handler for routeKey ${routeKey}.`,
};
};
At this point, file backend/index.ts looks like this:
import { APIGatewayProxyEvent, APIGatewayProxyHandler } from 'aws-lambda';
import { AWSError } from 'aws-sdk';
const AWS = require('aws-sdk');
AWS.config.update({ region: 'us-east-1' });
const docClient = new AWS.DynamoDB.DocumentClient();
const handleCreateNoteRequest = async (event: APIGatewayProxyEvent) => {
let requestBodyJson = '';
{
if (event.isBase64Encoded) {
requestBodyJson = (Buffer.from(event.body ?? '', 'base64')).toString('utf8');
} else {
requestBodyJson = event.body ?? '';
}
}
const requestBodyObject = JSON.parse(requestBodyJson) as { id: string, content: string };
await new Promise((resolve, reject) => {
docClient.put(
{
TableName: 'notes',
Item: {
id: requestBodyObject.id,
content: requestBodyObject.content
}
},
(err: AWSError) => {
if (err) {
console.error(err);
reject(err);
} else {
resolve(null);
}
});
});
return {
statusCode: 201,
headers: {
'content-type': 'text/plain'
},
body: 'Created.',
};
};
export const handler: APIGatewayProxyHandler = async (event) => {
const routeKey = `${event.httpMethod} ${event.pathParameters?.proxy}`;
if (routeKey === 'POST notes/') {
return handleCreateNoteRequest(event);
}
return {
statusCode: 404,
body: `No handler for routeKey ${routeKey}.`,
};
};
A first real API call
Running bash bin/deploy.sh once again will put the new code live, and afterwards, the following curl command should be successful:
> curl \
https://d1ka2fzxbv1rta.cloudfront.net/api/notes/ \
--data '{ "id": "123abc", "content": "Hello, World." }'
Created.
There’s no use in storing notes in the database if we cannot also retrieve them through the API, so let’s add another function to the backend code that fetches all existing note entries from the DynamoDB table:
import { ScanOutput } from 'aws-sdk/clients/dynamodb';
const handleGetNotesRequest = async () => {
const queryResult: ScanOutput = await new Promise((resolve, reject) => {
docClient.scan(
{ TableName: 'notes', Limit: 100 },
(err: AWSError, data: ScanOutput) => {
if (err) {
console.error(err);
reject(err);
} else {
resolve(data);
}
});
});
return {
statusCode: 200,
headers: {
'content-type': 'application/json'
},
body: JSON.stringify(queryResult.Items),
};
};
This looks a lot like the code for handleCreateNoteRequest, but this time, we do a DynamoDB table scan (very inefficient - again, no production code!), and return the result in the body of the API response.
Again, this needs to be integrated into the handler function, like this:
export const handler: APIGatewayProxyHandler = async (event) => {
const routeKey = `${event.httpMethod} ${event.pathParameters?.proxy}`;
if (routeKey === 'GET notes/') {
return handleGetNotesRequest();
}
if (routeKey === 'POST notes/') {
return handleCreateNoteRequest(event);
}
return {
statusCode: 404,
body: `No handler for routeKey ${routeKey}.`,
};
};
After running bash bin/deploy.sh once more, we can verify that the entry we’ve added previously with the POST request actually exists in the database table:
> curl https://d1ka2fzxbv1rta.cloudfront.net/api/notes/
[{"content":"Hello, World.","id":"123abc"}]
Looks good. However, using an application through curl isn’t exactly fun. Time to finally write a nice React frontend!
The frontend: Building a Single-Page Application with React and Redux
We start by setting up a code base using create-react-app, because that gives us a lot of sane defaults plus the boiler plate code required to wire everything up.
And of course, we choose the Redux + TypeScript flavor of create-react-app, allowing us to write code and handle UI state without headaches.
Generating the code base
The first step is to make sure that we have the most recent version of Node.js installed (and also use it):
> nvm install node
> nvm use node
As of this writing, this will give you Node.js 16. No need to intentionally pick a lower version, as we did for our AWS Lambda code base. The difference is that our Lambda code will end up being executed in an environment we don’t control, and which - as of this writing - is limited to Node.js 14. Our frontend Node.js code will only run in an environment we control, that is, our own system. From here, it will be transpiled into “boring” JavaScript code that even older web browsers understand - and which is then served via S3 and CloudFront. Thus, we are a lot less limited regarding the Node.js version we use while developing and building the code base.
Once you’ve switched to the most recent Node.js version using NVM, change to the topmost folder of your project directory, and on the same level as folders infrastructure and backend, run the following:
> npx create-react-app frontend --template redux-typescript
This will create a new folder frontend with a basic React app setup based on Redux Toolkit written in TypeScript. Let’s explore this foundation and see how we can turn it into a modern web frontend for our notes backend.
Exploring the React app code base
If we leave out the contents of folder node_modules, the frontend folder looks like this:
frontend
├── README.md
├── node_modules
│ └── ...
├── package-lock.json
├── package.json
├── public
│ ├── favicon.ico
│ ├── index.html
│ ├── logo192.png
│ ├── logo512.png
│ ├── manifest.json
│ └── robots.txt
├── src
│ ├── App.css
│ ├── App.test.tsx
│ ├── App.tsx
│ ├── app
│ │ ├── hooks.ts
│ │ └── store.ts
│ ├── features
│ │ └── counter
│ │ ├── Counter.module.css
│ │ ├── Counter.tsx
│ │ ├── counterAPI.ts
│ │ ├── counterSlice.spec.ts
│ │ └── counterSlice.ts
│ ├── index.css
│ ├── index.tsx
│ ├── logo.svg
│ ├── react-app-env.d.ts
│ ├── serviceWorker.ts
│ └── setupTests.ts
└── tsconfig.json
Let’s briefly walk through the most relevant stuff. File package.json contains all dependencies required to build, run, and test the app, plus the react-scripts package which contains the scripts and configuration used by the Create React App setup, which is what spares us a lot of yak shaving and allows us to build, run, and test the app right away, without any additional setup steps.
The contents in folder public are served by the built-in development web server that is launched by running npm run start. For example, file index.html is the template HTML document that provides the “root” div for React to occupy as it’s entry point to the DOM.
Folder src contains the actual React and Redux code, plus some CSS definitions and unit test files. Special attention should be paid to file index.ts, which contains the glue code between the DOM (as provided by the HTML document mentioned above) and the React components (contained in the other .jsx files).
Following the best practices suggested by the Redux projects, there is a feature/counter folder which contains all React and Redux code related to the one feature that the example code base implements, an interactive counter (which immediately greets you when running npm run start).
This is a very basic setup for a React + Redux + TypeScript app, but not a minimal one. For example, the app doesn’t set up a Service Worker, but contains the code to do so.
In order to better focus on implementing a notes app, let’s remove everything we don’t need. To do so, please remove everything that is NOT part of the following structure:
frontend
├── node_modules
│ └── ...
├── package-lock.json
├── package.json
├── public
│ ├── favicon.ico
│ ├── index.html
│ ├── logo192.png
│ ├── logo512.png
│ ├── manifest.json
│ └── robots.txt
├── src
│ ├── App.tsx
│ ├── app
│ │ ├── hooks.ts
│ │ └── store.ts
│ ├── features
│ ├── index.tsx
│ ├── react-app-env.d.ts
└── tsconfig.json
You can achieve this by running the following within folder frontend:
> rm -rf README.md src/features/counter src/{logo.svg,index.css,App.css,App.test.tsx,serviceWorker.ts,setupTests.ts}
Note that at this point, running the app via npm run start will no longer work, but of course we will bring it back into shape again.
As a final preparation step, let’s add a file .nvmrc in folder frontend, like this: echo "node" > .nvmrc.
Building a new feature
We will now create a new feature called “notes”, and we begin by creating a slice file.
Conceptually, a slice is one part of the global Redux state of a React application. For example, in a shopping app, the Redux state might consist of slices “session”, “viewedProducts”, “basket”, “checkout” etc.
Following Redux Toolkit best practices, a slice file is home to everything Redux-related for a given feature, for example the type definitions of the part of the Redux state that this slice handles. Let’s start with these, in file features/notes/notesSlice.ts:
import { createAsyncThunk, createSlice } from '@reduxjs/toolkit';
export interface Note {
readonly id: string,
readonly content: string
}
export interface NotesState {
readonly notes: Note[],
readonly errorMessage: null | string
}
const initialState: NotesState = {
notes: [],
errorMessage: null
};
The React app will interact with our backend through its two endpoints, one for creating new notes and one for fetching the list of existing notes. To do so, the React app will need to make API requests using fetch, and because these are asynchronous operations, we need to handle them in Thunks.
Redux Toolkit provides the createAsyncThunk helper to create a thunk, so let’s use that to create one for creating new notes through the backend API:
export const createNote = createAsyncThunk<Note, { readonly content: string }, { readonly rejectValue: { readonly errorMessage: string, readonly note: Note } }>(
'notes/create',
async (arg, thunkAPI) => {
const note: Note = { id: Math.random().toString(), content: arg.content };
return await fetch(
'/api/notes/',
{
method: 'POST',
body: JSON.stringify(note)
})
.then(response => {
if (response.status === 201) {
return note;
} else {
throw new Error(`Unexpected response from server (code ${response.status}).`);
}
})
.catch(function (error) {
console.error(error);
return thunkAPI.rejectWithValue({ errorMessage: error.message, note });
});
}
);
The helper function expects three type parameters: <Returned, ThunkArg, ThunkApiConfig>.
Typing a thunk
The first is the type of the payload of the Redux action that will be emitted when the thunk operation is successful. In our case, we pass type Note, because we create a new note object by rolling a random id using Math.random(), and adding the arg.content value which we receive when this thunk is dispatched by the React component (as we will see later).
For the second type parameter, ThunkArg, we pass a type definition inline: { readonly content: string }. This means that the arg parameter that needs to be passed when the thunk is dispatched must be an object with attribute content, of type string.
As the fetch operation can fail (because the API is not reachable, or returns an unexpected HTTP code), we possibly need to return a rejectValue instead of a Note. This then becomes the value of the action that is emitted in case of failure. We also want to type this return value, and we do this again inline as { readonly errorMessage: string, readonly note: Note }.
While you can see how the ThunkArg type parameter defines the type of parameter arg in our thunk function, let’s look at the slice definition to see how type parameters Returned and ThunkApiConfig are of use within our reducers.
We define the reducers for this slice with the createSlice helper, as follows:
export const notesSlice = createSlice({
name: 'notes',
initialState,
reducers: {
reset: () => initialState
},
extraReducers: (builder) => {
builder
.addCase(createNote.fulfilled, (state, action) => {
state.notes.unshift(action.payload);
state.errorMessage = null;
});
builder
.addCase(createNote.rejected, (state, action) => {
if (action.payload !== undefined) {
state.notes.unshift(action.payload.note);
state.errorMessage = action.payload.errorMessage;
}
});
},
});
export default notesSlice.reducer;
As you can see, we need to define the reducers for actions emitted by the thunk on the extraReducers attribute. The other attributes are probably self-explanatory: name sets the name of our slice, initialState is the content of this slice of the Redux state that is used when the application starts, and reducers is the place to define “normal”, non-thunk, synchronous reducers.
extraReducers is a function that gets passed a builder object, and using the addCase method of this object, we can define the reducer behaviour for actions that are emitted by the thunk. There are three possible actions that a thunk can emit: pending, rejected, and fulfilled. Here, we define reducers for the latter two.
fulfilled is emitted when the thunk is successful, that is, when it returns a value of the type that was defined for the Returned type parameter. If the thunk returns a value of the type defined for the ThunkApiConfig.rejectValue attribute, then the rejected action is emitted.
As createSlice uses the Immer library under the hood, we can safely modify the state object within our reducer code, without breaking the Redux rule to never modify the existing state. This is explained in detail in Writing Reducers with Immer.
Creating a React component
With the import statement, our own type definitions, the initial state, the thunk definition, and the slice definition in place, we can write a React component that makes use of the slice, in file frontent/src/features/notes/Notes.tsx:
import React, { useState } from 'react';
import { useAppSelector, useAppDispatch } from '../../app/hooks';
import { createNote } from './notesSlice';
export const Notes = () => {
const reduxState = useAppSelector(state => state);
const reduxDispatch = useAppDispatch();
const [newNoteContent, setNewNoteContent] = useState('');
return (
<div>
{
reduxState.notes.errorMessage !== null
&&
<strong>Error: {reduxState.notes.errorMessage}</strong>
}
<h1>Add note</h1>
<form onSubmit={ (e) => {
reduxDispatch(createNote({ content: newNoteContent }));
e.preventDefault();
}}>
<input
type='text'
className='form-control'
id='create-server-title'
placeholder=''
value={newNoteContent}
onChange={ (e) => setNewNoteContent(e.target.value) }
/>
<button type='submit' disabled={newNoteContent.length < 1}>
Add
</button>
</form>
</div>
);
};
Let’s walk through this code step by step.
Unsurprisingly, we start by importing React, plus a React hook that we need.
Note that useState is the hook for React’s local-component-state management, and has absolutely nothing to do with the Redux state.
To work with that, we import two other hooks which create-react-app generated for us: useAppSelector (which allows us to retrieve the current Redux state) and useAppDispatch (this is a function we can use to dispatch thunks and other Redux actions).
We then define React component Notes as normal JavaScript/TypeScript function - no need to write React Component classes anymore.
Next, we define consts reduxState and reduxDispatch. useAppSelector would allow us to get only that part of the state we are interested in within this component, but because our state is very small and simple, we take the whole thing. useAppDispatch(), in turn, gives us the Redux dispatch function.
Line const [newNoteContent, setNewNoteContent] = useState(''); is a typical example for local React component state which we don’t need to put into the Redux state. It gives us const newNoteContent, which is a string initialized with value '', and which will always contain the text typed in by the user in the “Create new note” form input field. To update its value, we use function setNewNoteContent.
Next, we return the DOM structure of our component using React’s JSX syntax. Note how we use value={newNoteContent} on line 28 to reflect the current local state value of newNoteContent within our input field, and onChange={ (e) => setNewNoteContent(e.target.value) } on line 29 to change the value of newNoteContent whenever the user changes the input field content. Lines 19-22 define what happens when the form is submitted:
<form onSubmit={ (e) => {
reduxDispatch(createNote({ content: newNoteContent }));
e.preventDefault();
}}>
We use the reduxDispatch function to dispatch thunk createNote, passing the current newNoteContent value as its argument, following the ThunkArg type definition in file notesSlice.ts, line 18.
Fixing TypeScript errors
If you use an IDE with good TypeScript support, you will notice how references to reduxState.notes are marked as erroneous, with message TS2339: Property 'notes' does not exist on type '{ counter: unknown; }'..
We need to fix this in file frontend/src/app/store.ts, by changing line 2 from
import counterReducer from '../features/counter/counterSlice';
to
import notesReducer from '../features/notes/notesSlice';
and line 6 from:
counter: counterReducer,
to
notes: notesReducer,
This sets up the Redux store correctly and allows TypeScript to understand the structure of the state object we retrieve through the useAppSelector hook.
While we are at it, let’s also remove two now unused imports, by changing line to this:
import { configureStore } from '@reduxjs/toolkit';
You can also remove lines 12-17, and should thus end up with this:
import { configureStore, ThunkAction, Action } from '@reduxjs/toolkit';
import notesReducer from '../features/notes/notesSlice';
export const store = configureStore({
reducer: {
notes: notesReducer,
},
});
export type AppDispatch = typeof store.dispatch;
export type RootState = ReturnType<typeof store.getState>;
Because we removed several auto-generated files earlier in the process, some code parts need to be fixed before we can launch the frontend app for the first time. In file frontend/src/index.tsx, remove this import on line 3:
import './index.css';
as well as this import on line 6:
import * as serviceWorker from './serviceWorker';
and then this comments and function call on lines 16-19:
// If you want your app to work offline and load faster, you can change
// unregister() to register() below. Note this comes with some pitfalls.
// Learn more about service workers: https://bit.ly/CRA-PWA
serviceWorker.unregister();
Now, switch to file frontend/src/App.tsx, and remove lines 2-4:
import logo from './logo.svg';
import { Counter } from './features/counter/Counter';
import './App.css';
Integrating the new feature
We can now integrate our new feature. To do so, remove all JSX code from the return statement starting on line 5, and replace it with <Notes />. If you are using an IDE with TypeScript and JavaScript support, the import statement this requires should be done automatically. In any case, this is how the final should now look:
import React from 'react';
import { Notes } from './features/notes/Notes';
function App() {
return (
<Notes />
);
}
export default App;
At this point, the frontend app is in a runnable state again, so let’s fire it up by running npm run start. This will open the app in a new browser window and show the following output:
Compiled successfully!
You can now view frontend in the browser.
Local: http://localhost:3000
On Your Network: http://192.168.0.228:3000
Note that the development build is not optimized.
To create a production build, use npm run build.
In your browser, you should be greeted by a very minimalistically designed “Add note” form with a single input field and a submit button that reads “Add” and only becomes available if you enter text in the input field.
Let’s try to add a first note and see what happens.
If you enter text and hit “Add”, you should see an error message at the top of the page reading “Error: Unexpected response from server (code 404).“. Using the inspection tool of your browser, it should look like this:
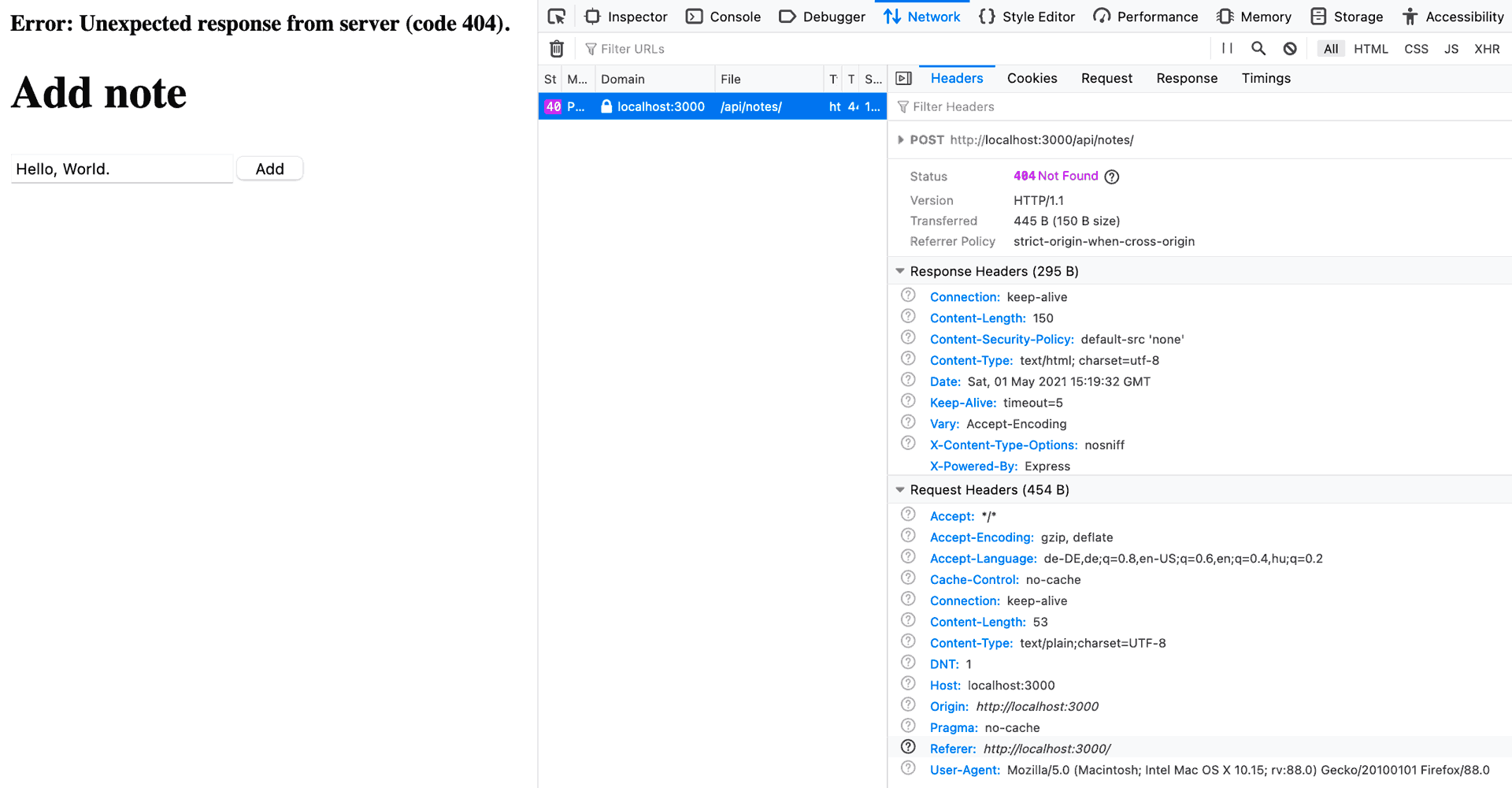
This comes from line 34 in file frontend/src/feature/notes/notesSlice.ts:
throw new Error(`Unexpected response from server (code ${response.status}).`);
It’s our thunk code throwing an error because the response status code from the server when requesting /api/notes with a POST is not 201 but 404.
Connecting to the API
This is expected. Our thunk code makes a request to path /api/notes, which means that the request goes to the same host and port on which the frontend app is served, that is, localhost:3000. But that’s not where our CloudFront > API Gateway > Lambda setup is running. Instead, it’s the local React Create App development webserver.
Here’s something we could do but won’t do. We could go to line 24 in file notesSlice.ts and change the address that fetch will send its request to from '/api/notes/' to https://d1ka2fzxbv1rta.cloudfront.net/api/ (of course, using YOUR cloudfront subdomain name). But we don’t do this because while it’s not technically incorrect, it won’t do the job as expected. This is because in this case, the client code running on origin localhost:3000 would make a request to origin d1ka2fzxbv1rta.cloudfront.net:443 - and that’s two different origins, triggering a security mechanism in the browser called Same-origin policy.
Also, once we put the frontend app into production, that is, into our infrastructure’s “frontend” S3 bucket which is served through the same CloudFront address as the API, we really do want the app to make a request to a path on its own origin.
But we also want this to work while we fiddle with the frontend app on our local system. Luckily, the development web server provided by Create React App offers an elegant solution - it can act as a proxy.
The way this works is that you can define a target address in file package.json, and every request the development web server cannot handle itself is forwarded to this address.
In order to set this up, add the following block to package.json, at the same level as dependencies, scripts etc.:
"proxy": "https://d1ka2fzxbv1rta.cloudfront.net"
(Once again, make sure to use YOUR CloudFront address, as shown by running terraform output in folder infrastructure).
You need to kill the development server by hitting CTRL-c, and start it anew. Adding a new note should now result in a 201 Created response from the backend.
The React frontend, however, doesn’t really react (no pun intended) if we add a new note. Let’s teach it to render a list of all notes, in file frontend/src/features/notes/Notes.tsx, by adding the following JSX code below the closing </form> tag:
<h1>Your notes</h1>
{reduxState.notes.notes.map(note => (
<div>
<small>{note.id}</small>
<br/>
{note.content}
<hr/>
</div>
))}
This will immediately work, because our reducer code on line 54 in file notesSlice.ts already extends the notes array in the Redux state upon successful completion of the thunk operation:
state.notes.unshift(action.payload);
At this point, there is only one last piece of functionality required to come full circle: When the frontend app starts, it should retrieve all existing notes from the backend, and populate the “Your notes” list with them.
Fetching notes
We implement this by adding another thunk, one that encapsulates the GET /api/notes/ operation, in file frontend/src/features/notes/notesSlice.ts:
export const fetchNotes = createAsyncThunk<Note[], void, { readonly rejectValue: { readonly errorMessage: string } }>(
'notes/fetch',
async (arg, thunkAPI) => {
return await fetch(
'/api/notes/',
{
method: 'GET'
})
.then(response => {
if (response.status === 200) {
return response.json();
} else {
throw new Error(`Unexpected response from server (code ${response.status}).`);
}
})
.catch(function (error) {
console.error(error);
return thunkAPI.rejectWithValue({ errorMessage: error.message });
});
}
);
This is relatively straightforward - fetch the notes from the backend, and return it upon success. Because the response from the backend already has the correct structure in this case, we can type this return value as Note[]. If something goes wrong, return the error message.
We also need reducers to handle the fulfilled and rejected actions that can be emitted by the thunk. We therefore extend the extraReducers function as follows:
builder
.addCase(fetchNotes.fulfilled, (state, action) => {
state.notes = action.payload;
});
builder
.addCase(fetchNotes.rejected, (state, action) => {
if (action.payload !== undefined) {
state.errorMessage = action.payload.errorMessage;
}
});
We can now extend the Notes component to make it dispatch the fetchNotes thunk when it is rendered for the first time. To do so, add the useEffect React hook to the first import statement in file Notes.tsx:
import React, { useState, useEffect } from 'react';
and make sure that the new thunk is imported, too:
import { createNote, fetchNotes } from './notesSlice';
Then, right before the return statement of function Notes, add the following:
useEffect(() => {
reduxDispatch(fetchNotes());
}, [reduxDispatch]);
This dispatches the thunk exactly once.
If you reload the frontend app in the browser and watch the network tab of your browsers inspection tool, you can see how the API request is triggered, the existing note entries are retrieved, and the user interface is updated accordingly.
A final deployment
There is only one thing left to do - we need to put the frontend app into production. This means building a production bundle from our source code, and upload it into the frontend S3 bucket. We achieve this by adding the following to file bin/deploy.sh, right below the PROJECT_NAME=... line and before the pushd "$DIR/../backend/" line:
pushd "$DIR/../frontend"
npm run build
aws s3 cp --recursive --acl public-read build/ "s3://$PROJECT_NAME-frontend/"
popd
With this, we can now fully deploy our application, by running bash bin/deploy.sh once again. Afterwards, open your CloudFront URL in the browser, and you will see your app frontend.
Congratulations, your serverless single-page app has been launched on the web!
Shutting down the project
You can get rid of all AWS infrastructure resources by simply running terraform destroy in folder infrastructure. Note, however, that you need to remove all contents from both S3 buckets beforehand, like this:
> rm --recursive s3://PLEASE-CHANGE-ME-frontend/
> rm --recursive s3://PLEASE-CHANGE-ME-backend/
Evaluating the approach
As explained in the introduction, in my opinion, a serverless single-page application approach isn’t necessarily a silver bullet which negates all other web app architectures. But it’s certainly a powerful solution with a unique set of strengths, and one I’m happy to have in my toolbox for future projects.
Let’s evaluate this architecture and tech stack on a couple of dimensions.
User Experience (UX): Our notes application is way too simple to stress this point, but for large web apps with complex UIs, correctly-built React apps offers a great user experience because they effectively avoid full-page-loads-on-every-click. This allows for very smooth state changes within the user interface, and it is certainly possible to provide an experience that is as good as a native desktop or mobile app.
Developer Experience (DX): Correctly and efficiently managing the state of complex user interfaces is no small feat. And it’s not necessarily fun in a language like JavaScript. But adding TypeScript and Redux into the mix makes all the difference. The type safety provided by TypeScript and the state mutation safety provided by Redux, together with the sanely opinionated patterns enforced by Redux Toolkit, turn a development process that could quickly become messy into a breeze. The hot-reload functionality of the Create React App development server allows for a fluid live-coding experience.
Hosting Experience: The promise of serverless hosting is that you can concentrate on building your app, without the need to “worry about” servers. This is certainly true in a general sense, and as this tutorial has shown you end up with an app that is fully hosted and therefore fully usable on the public web by only writing code, with no low-level server setup whatsoever required.
This level of convenience comes at a price, though: you are giving up a lot of control over the systems part of your project; you can manage some configuration settings and hope for the best when it comes to error reporting via CloudWatch, but that’s about it. For example, I tried to deploy the exact same setup in a different AWS region, and ended up with a strange CloudFront-and-S3 related error that prevented the frontend app from being served, and I wasn’t able to fully debug the problem, and simply couldn’t solve it. Without changing anything else, simply switching to AWS region us-east-1 resulted in a working app. Why? I have no idea.
Rollout Experience: Very much related to the Hosting Experience, but also a topic of its own in my opinion. I love how hosting the backend code on Lambda and the frontend code on S3 means that rolling out a new release boils down to building new JavaScript bundles and simply copying them to S3. This is an extremely fast process, and anyone who works with continuous deployment setups knows how being able to do releases quickly provides so much more than only the velocity itself.
Conclusion
So that’s that. I hope you enjoyed the ride and, if it feels like a useful approach, you can put it to good use for your next web app project.
If you have any questions or comments, then drop me a line on Twitter or send me an email at manuel@kiessling.net.